
DQ-MeeRKat
DQ-MeeRKat (Automating Data Quality Measurement with a Reference-Data-Profile-Annotated Knowledge Graph) is the successor of QuaIIe, which implements a novel method to measure data quality, but reuses the data source connections to load data from information sources with different data models. DQ-MeeRKat is available on GitHub where we refer to for further information.
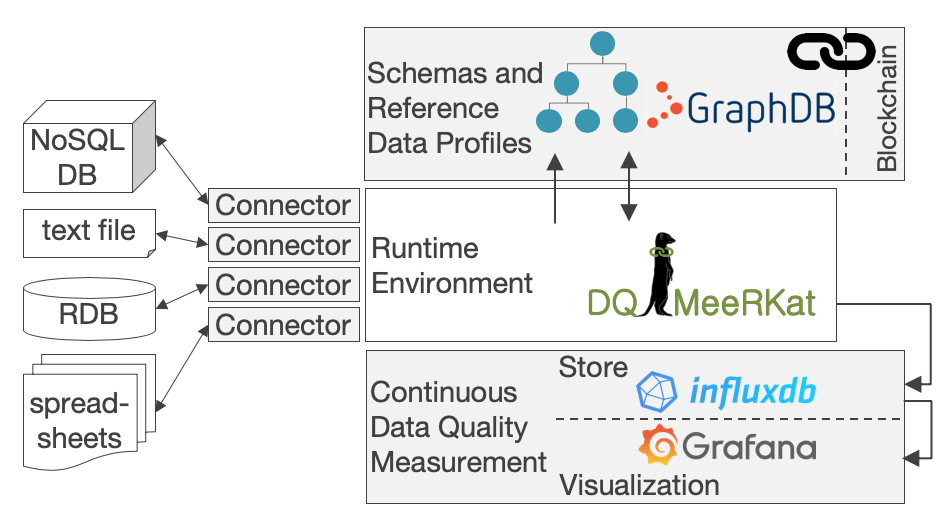
QuaIIe
QuaIIe (Quality Assessment for Integrated Information Environments) is a modular Java-based tool to assess the quality of an integrated information system, comprising content and schema quality. The demo provided on this website generates a quality report that includes four data quality dimensions on schema-level: completeness, correctness, pertinence, and minimality.
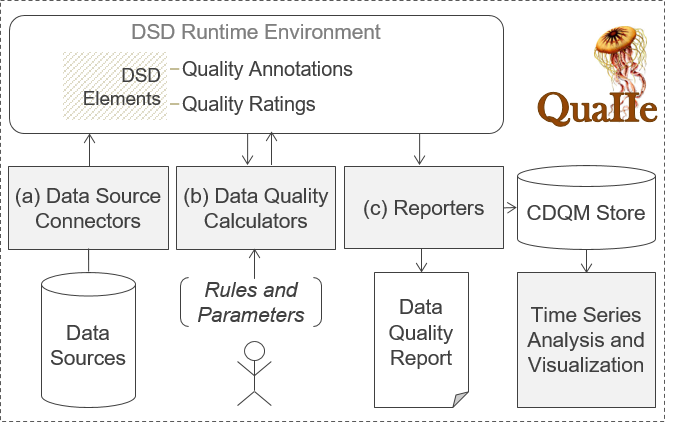
The figure shows the architecture of our modular Java-based tool QuaIIe for measuring IIS data-level and schema-level quality ad hoc and continuously. The tool consists of three abstract components: (a) data source connectors to establish an IS connection and to load schema information in form of DSD elements, (b) quality calculators that perform schema and data quality measurement and annotate this information to the DSD elements, and (c) reporters, which either generate a human and machine-readable quality report, or persist the continuous DQ measurements in a DB for later analysis. The tool has been implemented with a focus on maximum flexibility and extensibility, which makes it easy to add new connectors, calculators, or reporters, due to a standardized interface for each component.
Repeatability
In order to support repeatability of our experiments and evaluations, we provide an executable jar file that takes DSD files as input and generates the respective quality report as output.Download Qualle.jar and execute the following command:
DSD Vocabulary
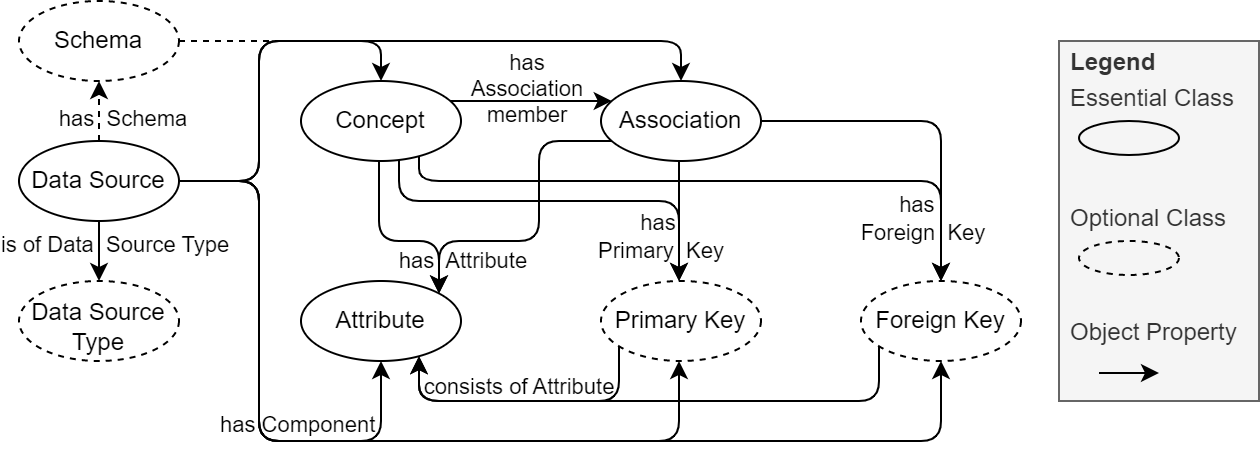
The Data Source Description Vocabulary (DSD) allows the representation of data sources and their internal structure independently of their type. The vocabulary is based on OWL, RDF, and RDF Schema and can be used to represent different types of data sources (e.g., relational or graph databases, document stores) and their (internal) semantics.
The figure above shows the classes available in DSD. A distinction between "essential" classes, that are necessary to describe a data source and "optional" classes is being made. For details on the individual classes, on the sub-classes not displayed in the figure, and on the object- and data properties provided by the vocabulary, we refer to the online documentation.
A publication on the current version of the DSD vocabulary is currently under review.
Online documentation
- DSD vocabulary online documentation (current version 4.0.0)
- DSD vocabulary online documentation (version 3.0.0)
The vocabulary for download:
Data Catalog Research
To the emerging scientific field of data catalogs, we conduct with fundamental research in the form of a systematic literature review, as well as with application-oriented research, such as the ontology layer "GOLDCASE".
Systematic Literature and Guidelines to Implementation
In 2021, we published Data Catalogs: A Systematic Literature Review and Guidelines to Implementation". Using the literature found during the review, besides implementation guidelines for data catalogs, the publication elaborates on the conceptual components of a data catalog.
As supplemental material to the publication, we provide the result of our systemaric literature review, in form of a literature list, for download.
GOLDCASE - A Generic ontology layer for data catalog semantics
During our research, we discovered, that the business context (see components found in the literature review) of many data catalog tools is lacking expressiveness. Often, business glossary terms or other kind of business attributes are used and relationships between two terms (e.g., a is a narrower term than b) are not possible. In 2022, we present GOLDCASE, which is an additional layer on-top of an existing data catalog and re-uses already existing information from there to achieve a higher expressiveness.
View online documentation for
GOLDCASE
Download GOLDCASE template
Missing Data Research
In 2021, we published our work on "Missing Data Patterns: From Theory to an Application in the Steel Industry" at the 33rd International Conference on Scientific and Statistical Database Management. Due to page limitations, we were not able to present our research (related work, extended evaluations) in full length. Therefore, we would like to provide supplemental material on this website for interested research to facilitate repeatability and further evaluations: Download supplemental material.Publications
More scientific background and a detailed description of our research work can be found in the following publications:- Lisa Ehrlinger, Christian Lettner, Johannes Himmelbauer: "Tackling Semantic Shift in Industrial Streaming Data Over Time". In: Proceedings of the Twelfth International Conference on Advances in Databases, Knowledge, and Data Applications (DBKDA 2020).
- Sheny Illescas Martinez: "Visualization and Management of Data Quality Metrics". Master's thesis. Johannes Kepler University Linz, 2020.
- Lisa Ehrlinger, Elisa Rusz, Wolfram Wöß: "A Survey of Data Quality Measurement and Monitoring Tools". CoRR, abs/1907.08138.
- Lisa Ehrlinger, Verena Haunschmid, Davide Palazzini, Christian Lettner: "A DaQL to Monitor Data Quality in Machine Learning Applications". In: 30th International Conference on Database and Expert Systems Applications - DEXA 2019, Linz Austria, August 26-29, 2019.
- Lisa Ehrlinger, Gudrun Huszar, Wolfram Wöß: "A Schema Readability Metric for Automated Data Quality Measurement". In: Proceedings of the 11th International Conference on Advances in Databases, Knowledge, and Data Applications (DBKDA 2019), Athens, Greece, June 02-06, 2019 (accepted).
- João Marcelo Borovina Josko, Lisa Ehrlinger, Wolfram Wöß: "Towards a Knowledge Graph to Describe and Process Data Defects". In: Proceedings of the 11th International Conference on Advances in Databases, Knowledge, and Data Applications (DBKDA 2019), Athens, Greece, June 02-06, 2019 (accepted).
- Lisa Ehrlinger, Werth Bernhard, Wolfram Wöß: "Automated Continuous Data Quality Measurement with QuaIIe". In: International Journal on Advances in Software, Volume 11, no. 3 & 4, December 2018, pp. 400-417. ISSN 1942-2628.
- Lisa Ehrlinger, Wolfram Wöß: "A Novel Data Quality Metric for Minimality". In: Data Quality and Trust in Big Data - 5th International Workshop, QUAT 2018, Held in Conjunction with WISE 2018, Dubai, UAE, November 12–15, 2018, Revised Selected Papers. Hakim Hacid, Quan Z. Sheng, Tetsuya Yoshida, Azadeh Sarkheyli, Rui Zhou (Eds.), Springer Lecture Notes in Computer Science, Volume 11235, 2019, pp.1-15. DOI 10.1007/978-3-030-19143-6.
- Lisa Ehrlinger, Wolfram Wöß: "Automated Schema Quality Measurement in Large-Scale Information Systems". In: Data Quality and Trust in Big Data - 5th International Workshop, QUAT 2018, Held in Conjunction with WISE 2018, Dubai, UAE, November 12–15, 2018, Revised Selected Papers. Hakim Hacid, Quan Z. Sheng, Tetsuya Yoshida, Azadeh Sarkheyli, Rui Zhou (Eds.), Springer Lecture Notes in Computer Science, Volume 11235, 2019, pp.16-31. DOI 10.1007/978-3-030-19143-6.
- Julia Hilber: "Data Quality Measurement in Wide-Column Stores". Master's thesis. Johannes Kepler University Linz, 2018.
- Lisa Ehrlinger, Bernhard Werth, Wolfram Wöß: "A Data Quality Assessment Tool for Integrated Information Systems". In: Proceedings of the 10th International Conference on Advances in Databases, Knowledge, and Data Applications (DBKDA 2018), Nice, France, May 20-25, 2018, pp. 21-31. ISBN 978-1-61208-637-8.
- Lisa Ehrlinger, Wolfram Wöß: "Automated Data Quality Monitoring". In: Proceedings of the MIT International Conference on Information Quality (MIT ICIQ 2017), Little Rock, AR, USA, October 06-07, 2017. John R. Talburt (Eds.), University of Arkansas, Little Rock (USA), 2017, pp. 15.1-15.9. ISBN 978-0-692-05026-2.
- Lisa Ehrlinger, Wolfram Wöß: "Semi-Automatically Generated Hybrid Ontologies for Information Integration". In: Joint Proceedings of the Posters and Demos Track of 11th International Conference on Semantic Systems – SEMANTiCS2015 and 1st Workshop on Data Science: Methods, Technology and Applications (DSci15), Vienna, September 15-17, 2015. Agata Filipowska, Ruben Verborgh, Axel Polleres (Eds.), CEUR Workshop Proceedings, Volume 1481, Sun SITE Central Europe (CEUR), Technical University of Aachen (RWTH), 2015, pp. 100-104.
A full list of publications can be found at my JKU website.
Contact
Dr. Lisa Ehrlinger (homepage)
Data Quality Researcher
Johannes Kepler University Linz
Institute for Application-oriented Knowledge Processing
Altenberger Straße 69
4040 Linz, Austria
E-Mail: lisa.ehrlinger@jku.at
Web: http://www.faw.jku.at
This application is an initiative of the Johannes Kepler University Linz in the course of the research project dasRes-Data Management and Analytics. The research reported in this paper has been supported by the Austrian Ministry for Transport, Innovation and Technology, the Federal Ministry for Digital and Economic Affairs, and the State of Upper Austria in the frame of the COMET center SCCH. (project homepage).